北邮人BT“说谢谢”刷分
前言
今天上午刚刚搬家到新的博客,这个博客使用 Markdown 语法写作,靠 DropBox 同步文章,感觉还是有点儿意思呢。之前的 Octopress 博客http://coding.yunbo.li访问速度实在是太差,而且到现在为止我还是没学会怎么在上面发布文章,这时 Farbox 出现了,索性转了过来。btw,以前的负能量小站已经迁移到了http://laodao.yunbo.li
目前这个系统的大体流程已经搞明白了,但是和其他博客系统一样,主题修改还是让我头疼。
不过也管不了那么多啦,等把一切都搞明白了再开始写不知道要等到什么时候了,索性就这样写吧,反正文章丢不了。
今天给大家带来的是一个 Python 写的小玩具,在北邮人 BT 上说谢谢刷魔力值。
在北邮人 BT 上有这么一条规则:

而且除了对每个种子只能说一次之外,系统对说谢谢这个功能没有其他限制。BYRBT 上大概有 4W 个种子,也就是说我们可以通过说谢谢得到 4W 魔力值。我们要做的就是靠 Python 来实现说谢谢的功能从而获得魔力值。
好,了解完思路,让我们进入实战环节。
说谢谢背后的原理
当我们对一个种子“说谢谢”的时候,浏览器干了什么?
首先,我们打开浏览器(以 Chrome 为例了,据说 FireFox 的 FireBug 也很好用),进入 BT 随便打开一个种子,比如我们打开这个http://bt.byr.cn/details.php?id=152137&hit=1,页面拉到种子信息那里,我们可以看到说谢谢按钮。

这时,请出我们今天的第一个大杀器——Chrome 开发者工具[^1]。
Chrome 开发者工具是随 Chrome 浏览器一起发布的面向开发人员的网页调适工具,通过它,我们可以看到网页背后的技术细节。在 Windows 下,我们可以用F12打开开发者工具,在 OSX 下,快捷键为Command+Option+I。
打开开发者工具后,我们会开到这样一个窗口。最上方是功能选项卡,不同的选项卡下对应着不同的功能,我们用的比较多的是Elements和Network选项卡。在Elements选项卡中,我们可以方便地以标准的树状结构浏览 HTML 元素,通常这对了解网页布局和网页元素的细节是很有帮助的。
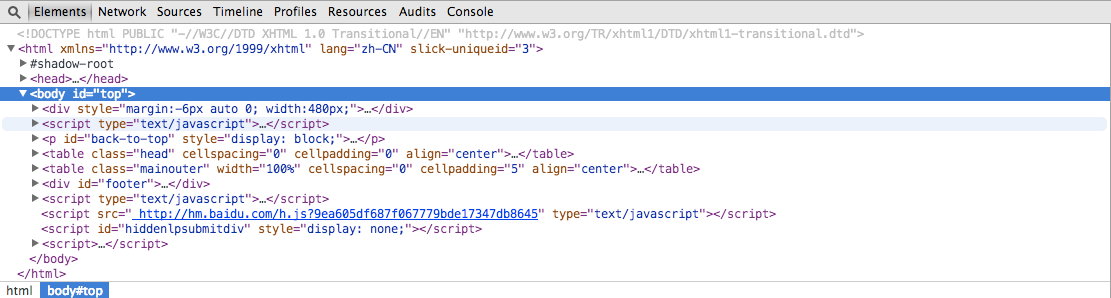
Network选项卡主要用来显示网页背后的数据交互,也就是用来查看 HTTP 请求。这里有两个按钮需要注意,首先是左上角的那个红点,它的左右和录音机的录制键差不多,红色表示记录状态,灰色表示非记录状态。它旁边的那个灰色叉子按钮是 Clear 键,用来删除已有的记录。在这一行的最右侧是Preserve log选项,如果它处于选中状态,那么即使网页刷新或者跳转,已有的记录依然会被保留。(默认情况下一旦页面刷新,已有记录会被清除)
现在我们要用到Network功能,所以切换到Network选项卡。然后,我们点击“说谢谢”按钮。我们观察到,Network选项卡下出现了一个条目:
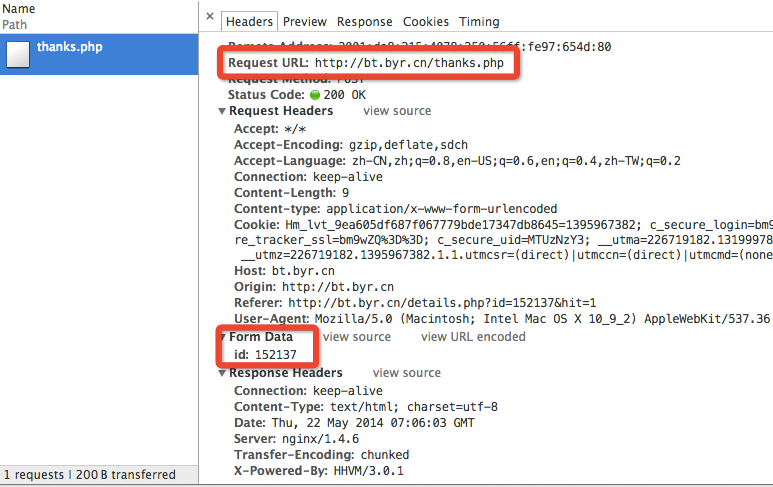
这里我们需要关注两个点,首先是Path==>thanks.php。然后是Method==>POST,也就是说,在我们点“说谢谢”按钮的时候,实际上是向thanks.php发送了一个POST请求[^2]。
点击这个 POST 请求查看详情,注意框框中的内容Request URL:http://bt.byr.cn/thanks.php和id:152137。第一个是我们发送 POST 请求的 URL,也就是说,是这个 URL 接受了浏览器发送的请求;第二个是请求过程中发送的参数(表),这里也就是种子 ID(还记得我们最开始打开了哪个 URL 吗?)
到此,我们已经清楚的了解了在点击“说谢谢”按钮时,浏览器都做了哪些事儿。那接下来就是用 Python 模拟这个动作了。
用 Python 实现
让我们整理一下思路,说谢谢的核心就是一个 POST 请求,这个请求有两个变量,Request URL是固定的,id是种子 ID。也就是说只要我们得到多少种子 ID 也就会得到相应的魔力值。那么接下来我们要做的就是抓取全站的种子 ID。
打开一个种子页面,然后右键->查看网页源代码,我们发现有很多类似这样的代码:
href="details.php?id=152186&hit=1"href="viewsnatches.php?id=152186"href="comment.php?action=add&pid=152186&type=torrent"href="download.php?id=152186"
这里面都包含了我们需要的种子 ID152186,所以方法就有了,只要通过正则表达式将网页源码中的种子 ID 匹配出来就可以了。
于是,我们祭出今天的第二个大杀器——BeatutifulSoup。
Beautiful Soup 是用 Python 写的一个 HTML/XML 的解析器,它可以很好的处理不规范标记并生成剖析树。通常用来分析爬虫抓取的 web 文档。对于 不规则的 Html 文档,也有很多的补全功能,节省了开发者的时间和精力。
简单说,BeautifulSoup 的作用是让我们更方便的在 HTML 代码中找东西。
材料已备齐,开搞
从这里开始我们按事件发生的先后顺序讲……要不然我怕讲乱了……
登录
登录是以后所有操作的基础,所以我们先看看登录的过程。打开 Chrome 开发者工具,找到 Network 选项,把 Preserve log 选中。然后我们登录一下 BT
很不幸,BT今天挂掉了,截图只能以后搞了
我们可以看到,登录的 POST 请求中发出了四个数据 username、password、imagestring 和 imagehash。前两个不用说,是你的用户名密码。imagestring 是你输入的验证码字符,imagehash 是与这张验证码图片对应的一个 hash 值,只有 hash 值和你输入的 string 值成功匹配时你才能登录。
好像说着说着就有点罗嗦了,有空慢慢写吧……to be continued